
How do you know that your model is overfitting just by seeing the training and validation loss?
As a standard practice, we hold 20% of the data points to be used for model validation, this data is referred to as a validation set. The other 80% of the data is used for training the model.
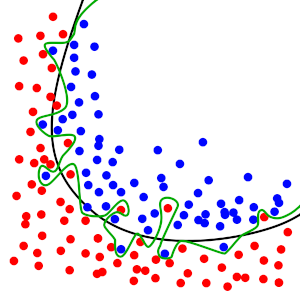
Now if we increase the number of epochs (the number of times the model sees the training data) without having much data, our model will start memorizing the data and its labels or at least certain parts of it.
Now when we look at the training and validation loss, we can see that initially the training loss is also decreasing and validation loss is also decreasing but after a certain number of epochs we will see that the training loss is still decreasing but the validation loss is increasing and this is the point where our model starts memorizing the data and its label and the model performance starts decreasing on the validation set. This is called overfitting.
So avoid training your model for longer durations and think that the model which is trained for a large number of epochs will give good results, always look out for training and validation losses during your model training. Some factors can lead to the overfitting of models (we will look at those in a different blog) but looking at training and validation loss can let us know if a model has started overfitting or not.
We want our model to perform well in the classification of unseen data by generalizing underlying patterns in the data but a model which has remembered data won’t be of any good.


